Architecture
Kubernetes is a combination of components distributed between two kind of nodes, Masters and Workers.
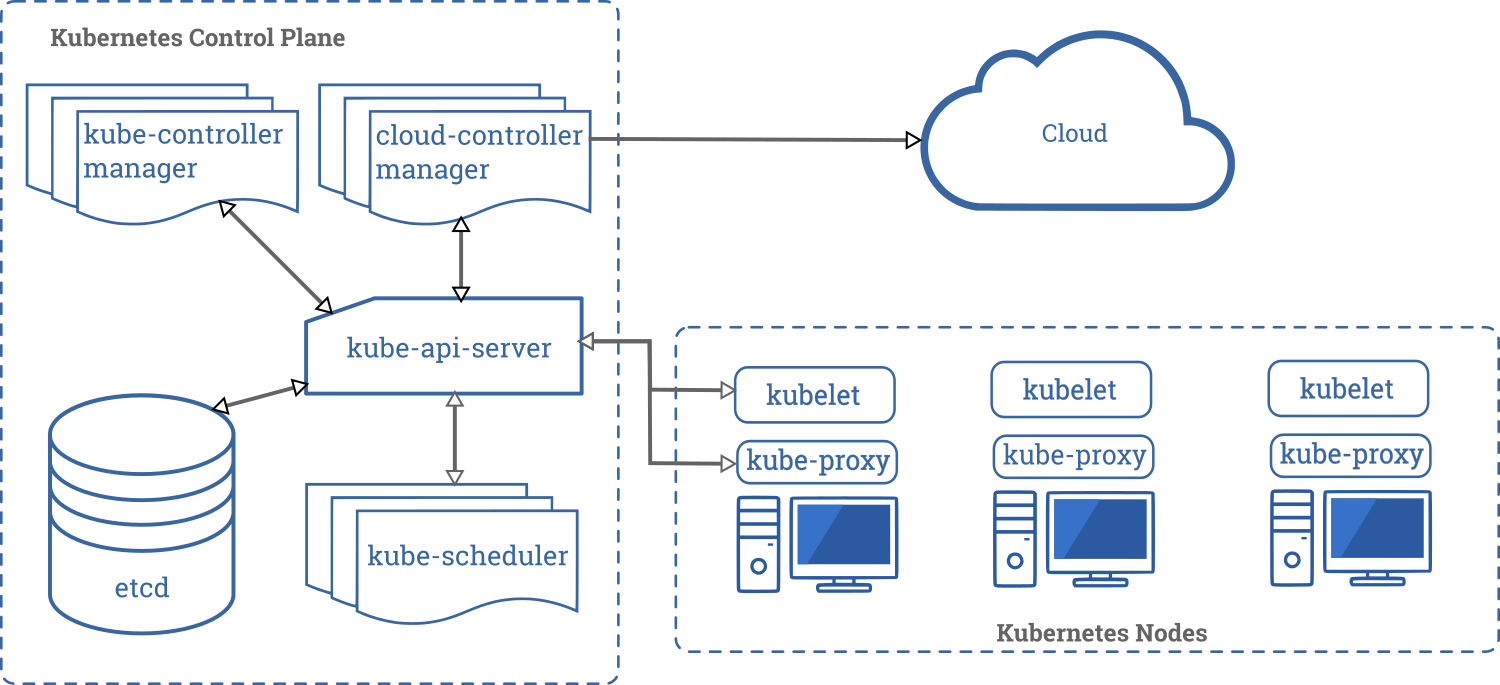
Master Nodes⚑
Master nodes or Kubernetes Control Plane are the controlling unit for the cluster. They manage scheduling of new containers, configure networking and provide health information.
To do so it uses:
-
kube-api-server exposes the Kubernetes control plane API validating and configuring data for the different API objects. It's used by all the components to interact between themselves.
-
etcd is a "Distributed reliable key-value store for the most critical data of a distributed system". Kubernetes uses Etcd to store state about the cluster and service discovery between nodes. This state includes what nodes exist in the cluster, which nodes they are running on and what containers should be running.
-
kube-scheduler watches for newly created pods with no assigned node, and selects a node for them to run on.
Factors taken into account for scheduling decisions include individual and collective resource requirements, hardware/software/policy constraints, affinity and anti-affinity specifications, data locality, inter-workload interference and deadlines.
-
kube-controller-manager runs the following controllers:
- Node Controller: Responsible for noticing and responding when nodes go down.
- Replication Controller: Responsible for maintaining the correct number of pods for every replication controller object in the system.
- Endpoints Controller: Populates the Endpoints object (that is, joins Services & Pods).
- Service Account & Token Controllers: Create default accounts and API access tokens for new namespaces.
-
cloud-controller-manager runs controllers that interact with the underlying cloud providers.
- Node Controller: For checking the cloud provider to determine if a node has been deleted in the cloud after it stops responding.
- Route Controller: For setting up routes in the underlying cloud infrastructure.
- Service Controller: For creating, updating and deleting cloud provider load balancers.
- Volume Controller: For creating, attaching, and mounting volumes, and interacting with the cloud provider to orchestrate volumes.
Worker Nodes⚑
Worker nodes are the units that hold the application data of the cluster. There can be different types of nodes: CPU architecture, amount of resources (CPU, RAM, GPU) or cloud provider.
Each node has the services necessary to run pods:
- Container Runtime: The software responsible for running containers (Docker, rkt, containerd, CRI-O).
- kubelet: The primary “node agent”. It works in terms of a PodSpec (a YAML or JSON object that describes it).
kubelettakes a set of PodSpecs from the masterskube-api-serverand ensures that the containers described are running and healthy. -
kube-proxy is the network proxy that runs on each node. This reflects services as defined in the Kubernetes API on each node and can do simple TCP and UDP stream forwarding or round robin across a set of backends.
kube-proxymaintains network rules on nodes. These network rules allow network communication to your Pods from network sessions inside or outside of your cluster.kube-proxyuses the operating system packet filtering layer if there is one and it's available. Otherwise, it will forward the traffic itself.
kube-proxy operation modes⚑
kube-proxy currently supports three different operation modes:
- User space: This mode gets its name because the service routing takes place in kube-proxy in the user process space instead of in the kernel network stack. It is not commonly used as it is slow and outdated.
- iptables: This mode uses Linux kernel-level Netfilter rules to configure all routing for Kubernetes Services. This mode is the default for kube-proxy on most platforms. When load balancing for multiple backend pods, it uses unweighted round-robin scheduling.
- IPVS (IP Virtual Server): Built on the Netfilter framework, IPVS implements Layer-4 load balancing in the Linux kernel, supporting multiple load-balancing algorithms, including least connections and shortest expected delay. This kube-proxy mode became generally available in Kubernetes 1.11, but it requires the Linux kernel to have the IPVS modules loaded. It is also not as widely supported by various Kubernetes networking projects as the iptables mode.
Kubectl⚑
The kubectl is the command line client used to communicate with the Masters.
Number of clusters⚑
You can run a given set of workloads either on few large clusters (with many workloads in each cluster) or on many clusters (with few workloads in each cluster).
Here's a table that summarizes the pros and cons of various approaches:
 Figure: Possibilities of number of clusters from learnk8s.io article
Figure: Possibilities of number of clusters from learnk8s.io article
Reference to the original article for a full read (it's really good!). I'm going to analyze only the Large shared cluster and Cluster per environment options, as they are the closest to my use case.
One Large shared cluster⚑
With this option, you run all your workloads in the same cluster. Kubernetes provides namespaces to logically separate portions of a cluster from each other, and in the above case, you could use a separate namespace for each application instance.
Pros:
-
Efficient resource usage: You need to have only one copy of all the resources that are needed to run and manage a Kubernetes cluster (master nodes, load balancers, Ingress controllers, authentication, logging, and monitoring).
-
Cheap: As you avoid the duplication of resources, you require less hardware.
-
Efficient administration: Administering a Kubernetes cluster requires:
- Upgrading the Kubernetes version
- Setting up a CI/CD pipeline
- Installing a CNI plugin
- Setting up the user authentication system
- Installing an admission controller
If you have only a single cluster, you need to do all of this only once.
If you have many clusters, then you need to apply everything multiple times, which probably requires you to develop some automated processes and tools for being able to do this consistently.
Cons:
-
Single point of failure: If you have only one cluster and if that cluster breaks, then all your workloads are down.
There are many ways that something can go wrong:
- A Kubernetes upgrade produces unexpected side effects.
- An cluster-wide component (such as a CNI plugin) doesn't work as expected.
- An erroneous configuration is made to one of the cluster components.
- An outage occurs in the underlying infrastructure.
A single incident like this can produce major damage across all your workloads if you have only a single shared cluster.
-
No hard security isolation: If multiple apps run in the same Kubernetes cluster, this means that these apps share the hardware, network, and operating system on the nodes of the cluster.
Concretely, two containers of two different apps running on the same node are technically two processes running on the same hardware and operating system kernel.
Linux containers provide some form of isolation, but this isolation is not as strong as the one provided by, for example, virtual machines (VMs). Under the hood, a process in a container is still just a process running on the host's operating system.
This may be an issue from a security point of view — it theoretically allows unrelated apps to interact with each other in undesired ways (intentionally and unintentionally).
Furthermore, all the workloads in a Kubernetes cluster share certain cluster-wide services, such as DNS — this allows apps to discover the Services of other apps in the cluster.
It's important to keep in mind that Kubernetes is designed for sharing, and not for isolation and security.
-
No hard multi-tenancy: Given the many shared resources in a Kubernetes cluster, there are many ways that different apps can "step on each other's toes".
For example, an app may monopolize a certain shared resource, such as the CPU or memory, and thus starve other apps running on the same node.
Kubernetes provides various ways to control this behaviour, however it's not trivial to tweak these tools in exactly the right way, and they cannot prevent every unwanted side effect either.
-
Many users: If you have only a single cluster, then many people in your organisation must have access to this cluster.
The more people have access to a system, the higher the risk that they break something.
Within the cluster, you can control who can do what with role-based access control (RBAC) — however, this still can't prevent that users break something within their area of authorisation.
Cluster per environment⚑
With this option you have a separate cluster for each environment.
For example, you can have a dev, test, and prod cluster where you run all the application instances of a specific environment.
-
Isolation of the *prod environment*: In general, this approach isolates all the environments from each other — but, in practice, this especially matters for the prod environment.
The production versions of your app are now not affected by whatever happens in any of the other clusters and application environments.
So, if some misconfiguration creates havoc in your dev cluster, the prod versions of your apps keep running as if nothing had happened.
-
Cluster can be customised for an environment:
You can optimise each cluster for its environment — for example, you can:
* Install development and debugging tools in the dev cluster. * Install testing frameworks and tools in the test cluster. * Use more powerful hardware and network connections for the prod cluster.This may improve the efficiency of both the development and operation of your apps. * Lock down access to prod cluster: Nobody really needs to do work on the prod cluster, so you can make access to it very restrictive.
Cons:
-
More administration and resources: In comparison with the single cluster.
-
Lack of isolation between apps: The main disadvantage of this approach is the missing hardware and resource isolation between apps.
Unrelated apps share cluster resources, such as the operating system kernel, CPU, memory, and several other services.
As already mentioned, this may be a security issue.
-
App requirements are not localised: If an app has special requirements, then these requirements must be satisfied in all clusters.
Conclusion⚑
If you don't need environment isolation and are not afraid of upgrading the Kubernetes cluster, go for the single cluster, otherwise use a cluster per environment.