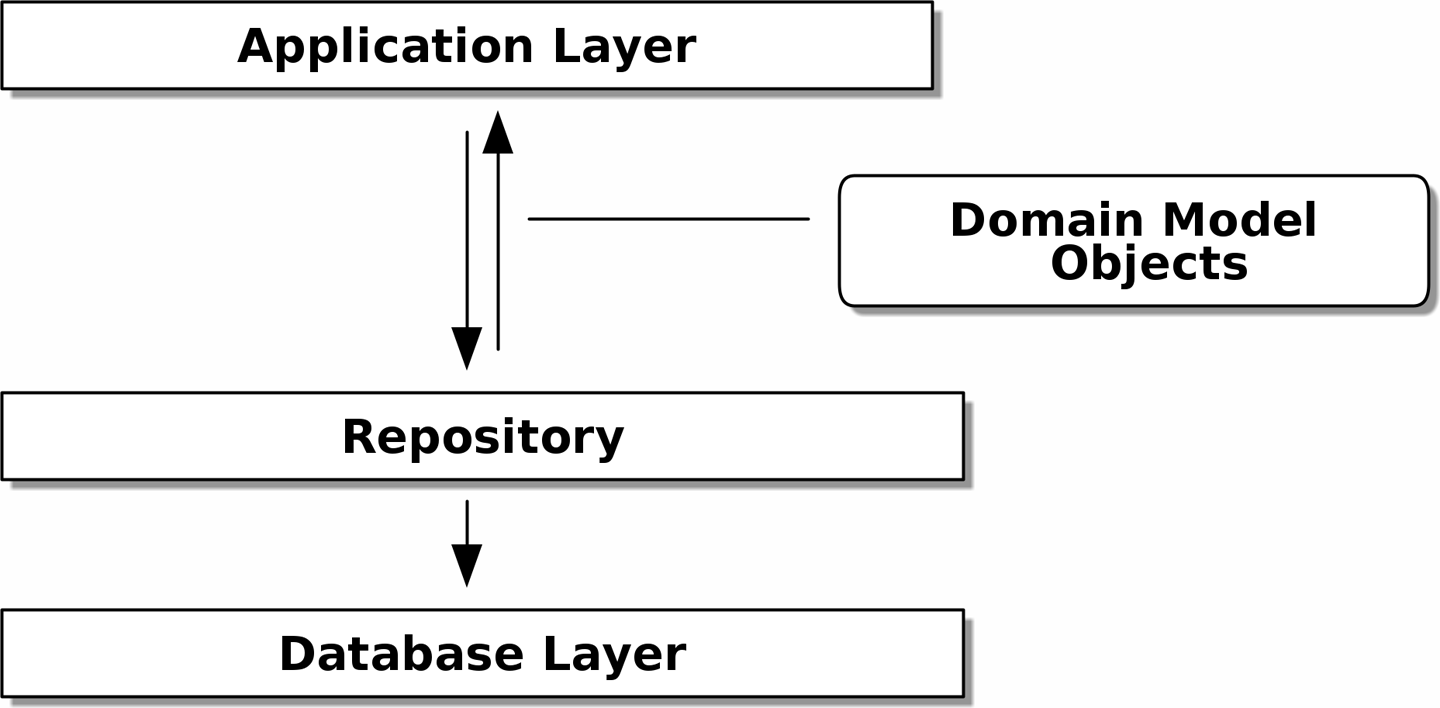
Repository Pattern
The repository pattern is an abstraction over persistent storage, allowing us to decouple our model layer from the data layer. It hides the boring details of data access by pretending that all of our data is in memory.
TL;DR
If your app is a basic CRUD (create-read-update-delete) wrapper around a database, then you don't need a domain model or a repository. But the more complex the domain, the more an investment in freeing yourself from infrastructure concerns will pay off in terms of the ease of making changes.
Advantages:
- We get a simple interface, which we control, between persistent storage and our domain model.
- It's easy to make a fake version of the repository for unit testing, or to swap out different storage solutions, because we've fully decoupled the model from infrastructure concerns.
- Writing the domain model before thinking about persistence helps us focus on the business problem at hand. If we need to change our approach, we can do that in our model, without needing to worry about foreign keys or migrations until later.
- Our database schema is simple because we have complete control over how we map our object to tables.
- Speeds up and makes more clean the business logic tests.
- It's easy to implement.
Disadvantages:
- An ORM already buys you some decoupling. Changing foreign keys might be hard, but it should be pretty easy to swap between MySQL and Postres if you ever need to.
- Maintaining ORM mappings by hand requires extra work and extra code.
- An extra layer of abstraction is introduced, and although we may hope it will reduce complexity overall, it does add complexity locally. Furthermore it adds the WTF factor for Python programmers who've never seen this pattern before.
[Intermediate optional step] Making the ORM depend on the Domain model
Applying the DIP to the data access we aim to have no dependencies between architectural layers. We don't want infrastructure concerns bleeding over into our domain model and slowing down our unit tests or our ability to make changes. So we'll have an onion architecture.
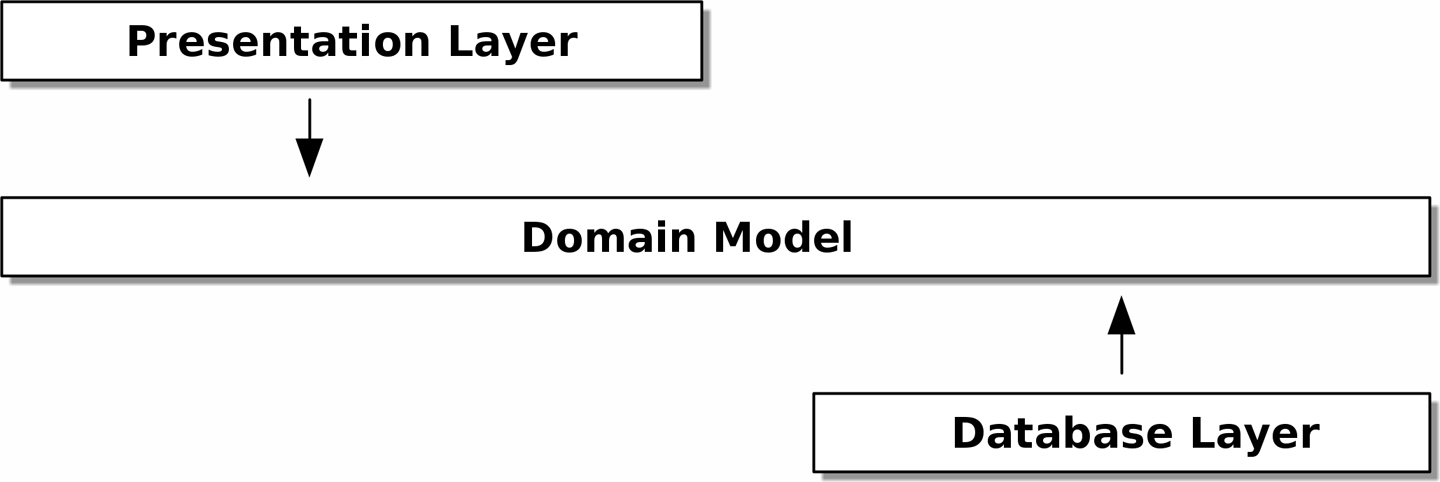
If you follow the typical SQLAlchemy tutorial, you'll end up with a "declarative" syntax where the model tightly depends on the ORM. The alternative is to make the ORM import the domain model, defining our database tables and columns by using SQLAlchemy's abstractions and magically binding them together with a mapper function.
from SQLAlchemy.orm import mapper, relationship
import model
metadata = MetaData()
task = Table(
'task', metadata,
Colum('id', Integer, primary_key=True, autoincrement=True),
Column('description', String(255)),
Column('priority', Integer, nullable=False),
)
def start_mappers():
task_mapper = mapper(model.Task, task)
The end result is be that, if we call start_mappers, we will be able to easily load and save domain model instances from and to the database. But if we never call that function, our domain model classes stay blissfully unaware of the database.
When you're first trying to build your ORM config, it can be useful to write tests for it, though we probably won't keep them around for long once we've got the repository abstraction.
def test_task_mapper_can_load_tasks(session):
session.execute(
'INSERT INTO task (description, priority) VALUES'
'("First task", 3),'
'("Urgent task", 5),'
)
expected = [
model.Task("First task", 3),
model.Task("Urgent task", 5),
]
assert session.query(model.Task).all() == expected
def test_task_mapper_can_save_lines(session):
new_task = model.Task("First task", 3)
session.add(new_task)
session.commit()
rows = list(session.execute('SELECT description, priority FROM "task"'))
assert rows == [("First task", 3)]
The most basic repository has just two methods: add() to put a new item in the repository, and get() to return a previously added item. We stick to using these methods for data access in our domain and our service layers.
import abc
import model
class AbstractRepository(abc.ABC):
@abc.abstractmethod
def add(self, task: model.Task):
raise NotImplementedError
@abc.abstractmethod
def get(self, reference) -> model.Task:
raise NotImplementedError
The @abc.abstractmethod is one of the only things that makes ABCs actually "work" in Python. Python will refuse to let you instantiate a class that does not implement all the abstractmethods defined in its parent class.
As always, we start with a test. This would probably be classified as an integration test, since we're checking that our code (the repository) is correctly integrated with the database; hence, the tests tend to mix raw SQL with calls and assertions on our own code.
# Test .add()
def test_repository_can_save_a_task(session):
task = model.Task("First task", 3)
repo = repository.SqlAlchemyRepository(session)
repo.add(task)
session.commit()
rows = list(session.execute(
'SELECT description, priority FROM "tasks"'
))
assert rows == [("First task", 3)]
# Test .get()
def insert_task(session):
session.execute(
'INSERT INTO tasks (description, priority)'
'VALUES ("First task", 3)'
)
[[task_id]] = session.execute(
'SELECT id FROM tasks WHERE id=:id',
dict(id='1'),
)
return task_id
def test_repository_can_retrieve_a_task(session):
task_id = insert_task()
repo = repository.SqlAlchemyRepository(session)
retrieved = repo.get(task_id)
expected = model.Task('1', 'First task', 3)
assert retrieved == expected # Task.__eq__ only compares reference
assert retrieved.description == expected.description
assert retrieved.priority == expected.priority
Note that we leave the .commit() outside of the repository and make it the responsibility of the caller.
Whether or not you write tests for every model is a judgment call. Once you have one class tested for create/modify/save, you might be happy to go on and do the others with a minimal round-trip test, or even nothing at all, if they all follow a similar pattern.
SqlAlchemyRepository is the repository that matches those tests.
class SqlAlchemyRepository(AbstractRepository):
def __init__(self, session):
self.session = session
def add(self, task: model.Task):
self.session.add(task)
def get(self, id: str) -> model.Task:
return self.session.query(model.Task).get(id)
def list(self) -> List(model.Task):
return self.session.query(model.Task).all()
Building a fake repository for tests is now trivial.
class FakeRepository(AbstractRepository):
def __init__(self, tasks: List(model.Task)):
self._tasks = set(tasks)
def add(self, task: model.Task):
self.tasks.add(task)
def get(self, id: str) -> model.Task:
return next(task for task in self._tasks if task.id == id)
def list(self) -> List(model.Task):
return list(self._tasks)
Warnings⚑
Don't include the properties the ORM introduces into the model of the entities, otherwise you're going to have a bad debugging time.
If we use the ORM to back populate the children attribute in the model of Task, don't add the attribute in the __init__ method arguments, but initialize it inside the method:
class Task:
def __init__(self, id: str, description: str) -> None:
self.id = id
self.description = description
self.children Optional[List['Task']]= None
References⚑
- The repository pattern chapter of the Architecture Patterns with Python book by Harry J.W. Percival and Bob Gregory.