Domain Driven Design
Domain-driven Design(DDD) is the concept that the structure and language of your code (class names, class methods, class variables) should match the business domain.
Domain-driven design is predicated on the following goals:
- Placing the project's primary focus on the core domain and domain logic.
- Basing complex designs on a model of the domain.
- Initiating a creative collaboration between technical and domain experts to iteratively refine a conceptual model that addresses particular domain problems.
It aims to fix these common pitfalls:
-
When asked to design a new system, most developers will start to build a database schema, with the object model treated as an afterthought. Instead, behaviour should come first and drive our storage requirements.
-
Business logic comes spread throughout the layers of our application, making it hard to identify, understand and change.
-
The feared big ball of mud.
They are avoided through:
-
Encapsulation an abstraction: understanding behavior encapsulation as identifying a task that needs to be done in our code and giving that task to an abstraction, a well defined object or function.
Encapsulating behavior with abstractions is a powerful decoupling tool by hiding details and protecting the consistency of our data, making code more expressive, more testable and easier to maintain.
-
Layering: When one function, module or object uses another, we say that one depends on the other creating a dependency graph. In the big ball of mud the dependencies are out of control, so changing one node becomes difficult because it has the potential to affect many other parts of the system.
Layered architectures are one way of tackling this problem by dividing our code into discrete categories or roles, and introducing rules about which categories of code can call each other.
By following the Dependency Inversion Principle (the D in SOLID), we must ensure that our business code doesn't depend on technical details, instead, both should use abstractions. We don't want high-level modules ,which respond to business needs, to be slowed down because they are closely coupled to low-level infrastructure details, which are often harder to change. Similarly, it is important to be able to change the infrastructure details when we need to without needing to make changes to the business layer.
Refactoring old code is expensive
You may be tempted to migrate all your old code to this architecture once you fall in love with it. Truth being told, it's the best way to learn how to use it, but it's time expensive too! The last refactor I did required a change of 60% of the code. The upside is that I reduced the total lines of code a 25%.
Domain modeling⚑
Keeping in mind that Domain is the problem you are trying to solve, and Model A system of abstractions that describes selected aspects of a domain and can be used to solve problems related to that domain. The domain model is the mental map that business owners have of their businesses.
It's set in a context and it's defined through ubiquitous language. A language structured around the domain model and used by all team members to connect all the activities of the team with the software.
To successfully build a domain model we need to:
- Explore the domain language: Have an initial conversation with the business expert and agree on a glossary and some rules for the first minimal version of the domain model. Wherever possible, ask for concrete examples to illustrate each rule.
-
Testing the domain models: Translate each of the rules gathered in the exploration phase into tests. Keeping in mind:
-
The name of our tests should describe the behaviour that we want to see from the system.
-
The test level in the testing pyramid should be chosen following the high and low gear metaphor.
-
-
Code the domain modeling object: Choose the objects that match the behavior you are testing keeping in mind:
- The names of the classes, methods, functions and variables should be taken from the business jargon.
Domain modeling objects⚑
-
Value object: Any domain object that is uniquely identified by the data it holds, so it has no conceptual identity. They should be treated as immutable. We can still have complex behaviour in value objects. In fact, it's common to support operations, for example, mathematical operators.
dataclasses are great for value objects because:
- They follow the value equality property (two objects with the same attributes are treated as equal).
- Can be defined as immutable with the
frozen=Truedecorator argument. - They define the
__hash__magic method based on the attribute values.__hash__is used by Python to control the behaviour of objects when you add them to sets or use them as dict keys.
@dataclass(frozen=True) class Name: first_name: str surname: str assert Name('Harry', 'Percival') == Name('Harry', 'Percival') assert Name('Harry', 'Percival') != Name('Bob', 'Gregory') -
Entity: An object that is not defined by it's attributes, but rather by a thread of continuity and it's identity. Unlike values, they have identity equality. We can change their values, and they are still recognizably the same thing.
class Person: def __init__(self, name: Name): self.name = name def test_barry_is_harry(): harry = Person(Name("Harry", "Percival")) barry = harry barry.name = Namew("Barry", "Percival") assert harry is barry and barry is harryWe usually make this explicit in code by implementing equality operators on entities:
class Person: ... def __eq__(self, other): if not isinstance(other, Person): return False return other.identifier == self.identifier def __hash__(self): return hash(self.identifier)Python's
__eq__magic method defines the behavior of the class for the==operator.For entities, the simplest option is to say that the hash is
None, meaning that the object is not hashable so it can't be used as dictionary keys. If for some reason you need that, the hash should be based on the attribute that identifies the object over the time. You should also try to somehow make that attribute read-only. Beware, editing__hash__without modifying__eq__is tricky business. -
Service: Functions that hold operations that don't conceptually belong to any object. We take advantage of the fact that Python is a multiparadigm language.
-
Exceptions: Hold constrains imposed over the objects by the business.
Domain modeling patterns⚑
To build a rich robust object model that is decoupled from technical concerns we need to build persistence-ignorant code that uses stable APIs around our domain so we can refactor aggressively.
This is achieved through these design patterns:
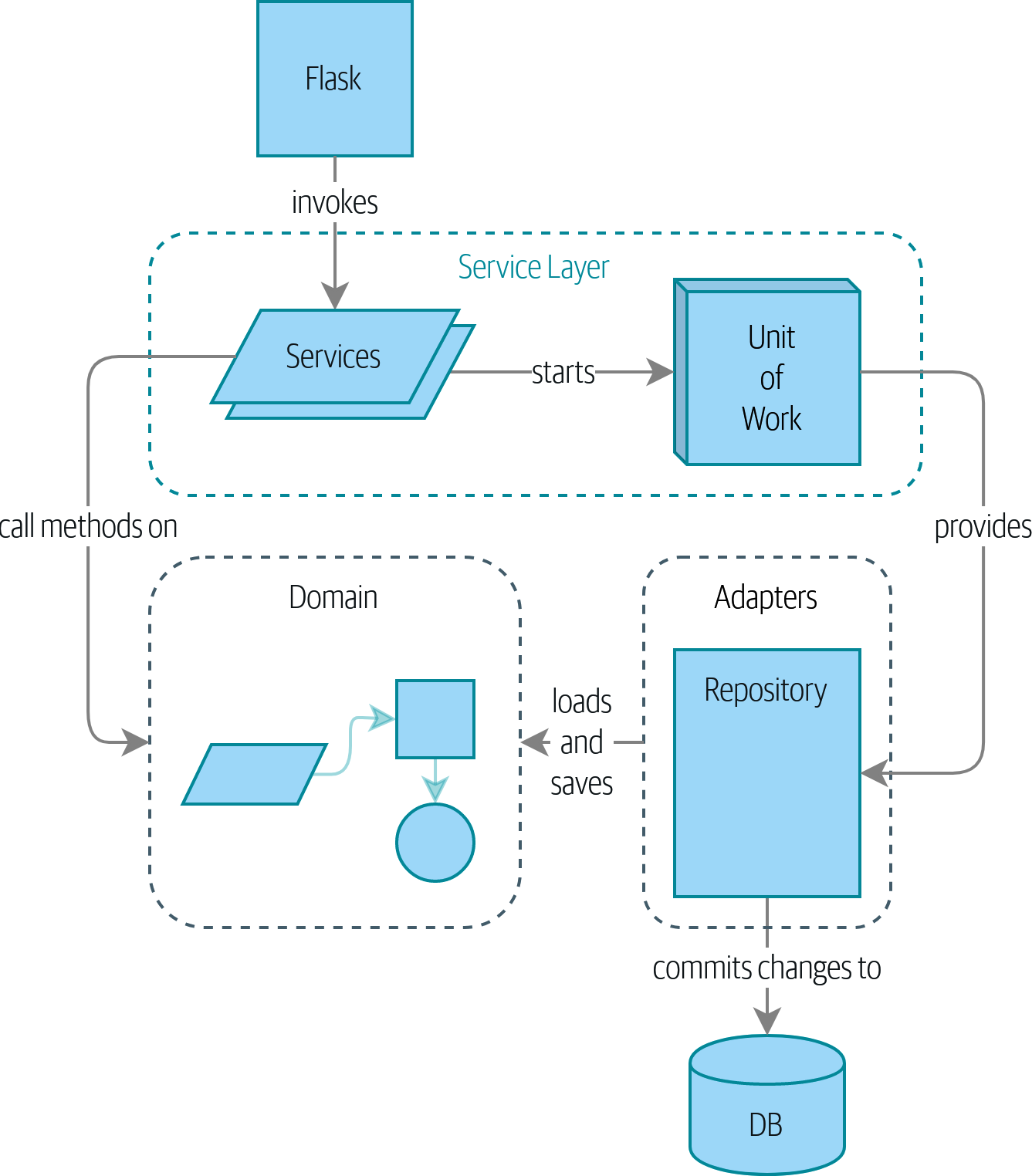
- Repository pattern: An abstraction over the idea of persistent storage.
- Service Layer pattern: Clearly define where our use case begins and ends.
- Unit of work pattern: Provides atomic operations.
- Aggregate pattern: Enforces integrity of our data.
Unconnected thoughts⚑
Domain model refactor⚑
Refactoring an existing project into the domain driven design architecture is not a nice task, These are the steps I've followed:
- If the domain models are coupled with the ORM, build a basic repository that makes the ORM dependent on the model. For the first version, ignore the relations between the models, just implement the
.addand.getmethods to persist and read the models from the persistent storage solution. - Create a
FakeRepositorywith similar functionality to start building the Service Layer. - Inspect the entrypoints of your program and for each orchestration action create a service (always tests first).
Building blocks⚑
- Aggregate: A collection of objects that are bound together by a root entity, otherwise known as an aggregate root. The aggregate root guarantees the consistency of changes being made within the aggregate by forbidding external objects from holding references to it's members.
- Domain Event: A domain object that defines an event.
- Repository: Methods for retrieving domain objects should delegate to a specialized Repository object such that alternative storage implementations may be easily interchanged.
- Factory: Methods for creating domain objects should delegate to a specialized Factory object such that alternative implementations may be easily interchanged.
Injection of fakes in edge to edge tests⚑
If you are developing your program with this design pattern, you'll have fake versions of your adapters. When testing the edge to edge tests, you're going to use the fakes when there is no easy way to do a correct end to end test (if for example you need to bring up a service that is complex to configure).
I've been banging my head against the keyboard until I've figured how to do it for click command line tests.
References⚑
- Architecture Patterns with Python by Harry J.W. Percival and Bob Gregory.
- Wikipedia article
Further reading⚑
Books⚑
- Domain-Driven Design by Eric Evans.
- Implementing Domain-Driven Design by Vaughn Vermon.